在Linux服务器系统中,文本处理是一项基本技能。无论您是开发人员、系统管理员还是只是Linux爱好者,了解如何操作和提取文本都可以显着提高您的工作效率。本文重点讨论文本处理的一个特定方面:提取位于两个特定单词之间的文本。我们将探索各种命令行工具和技术来实现这一目标,并提供实际示例。
www.a5idc.net在深入研究这些方法之前,了解我们正在处理的文本非常重要。Linux中的文本可以来自多种来源:文件、命令输出、日志等。这里讨论的技术适用于所有这些类型。
Linux中的多个工具可用于文本提取,但我们将重点关注三个:grep、awk和sed。这些是大多数Linux发行版上预安装的强大文本处理实用程序。
1.使用grep
grep是一个命令行实用程序,用于在纯文本数据中搜索与正则表达式匹配的行。虽然grep通常用于搜索特定模式,但它也可用于提取文本。
例子:
假设您有一个包含以下内容的文件example.txt:
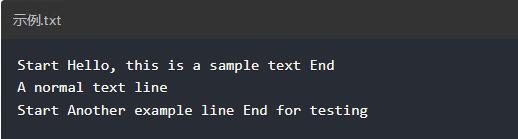
要提取“Start”和“End”之间的文本,您可以使用:
grep -oP 'Start\K.*?(?=End)' example.txt
此命令使用Perl兼容的正则表达式(PCRE)来匹配“Start”和“End”之间的任何文本。
2.使用awk
awk是一种用于操作数据和生成报告的脚本语言。它是Linux中文本处理的强大工具。
例子:
使用相同的example.txt,要使用提取“Start”和“End”之间的文本awk,您可以使用:
awk -F'Start|End' '{print $2}' example.txt
在这里,我们将字段分隔符-F设置为“开始”或“结束”并打印第二个字段,即其间的文本。
3.使用sed
sed是一个用于过滤和转换文本的流编辑器。它是Linux中文本操作的另一个重要工具。
例子:
再次,使用example.txt文件,要使用提取“Start”和“End”之间的文本sed,您可以使用:
sed -n 's/.*Start\(.*\)End.*/\1/p' example.txt
此sed命令结合使用模式匹配和反向引用来捕获和打印所需的文本。
4.实际应用
上述方法不仅仅是学术性的。以下是此类文本提取有用的一些实际场景:
日志分析:从日志文件中提取特定信息,如时间戳、错误消息等。
数据解析:在脚本中,解析命令的输出或文件内容以获取特定数据。
报告生成:通过提取相关部分从原始数据文件创建自定义报告。
5.技巧和窍门
正则表达式:掌握正则表达式是在Linux中进行有效文本处理的关键。
测试您的命令:在将命令应用于关键数据之前,始终在示例文件上测试您的命令。
组合工具:有时,组合两个或多个工具(例如使用grep和awk)可以产生强大的结果。
在Linux服务器系统中提取两个特定单词之间的文本是一个常见的需求,掌握这项技能可以大大简化许多文本处理任务。grep、awk和`sed的使用提供了一个强大的工具包,用于处理各种文本提取场景。每种工具都有其优点,选择取决于您任务的具体要求。
请记住,提供的示例只是一个起点。真正的力量在于调整和组合这些技术以满足您的独特需求。随着您对这些工具越来越熟悉,您会发现自己可以轻松地无缝地完成复杂的文本处理任务。